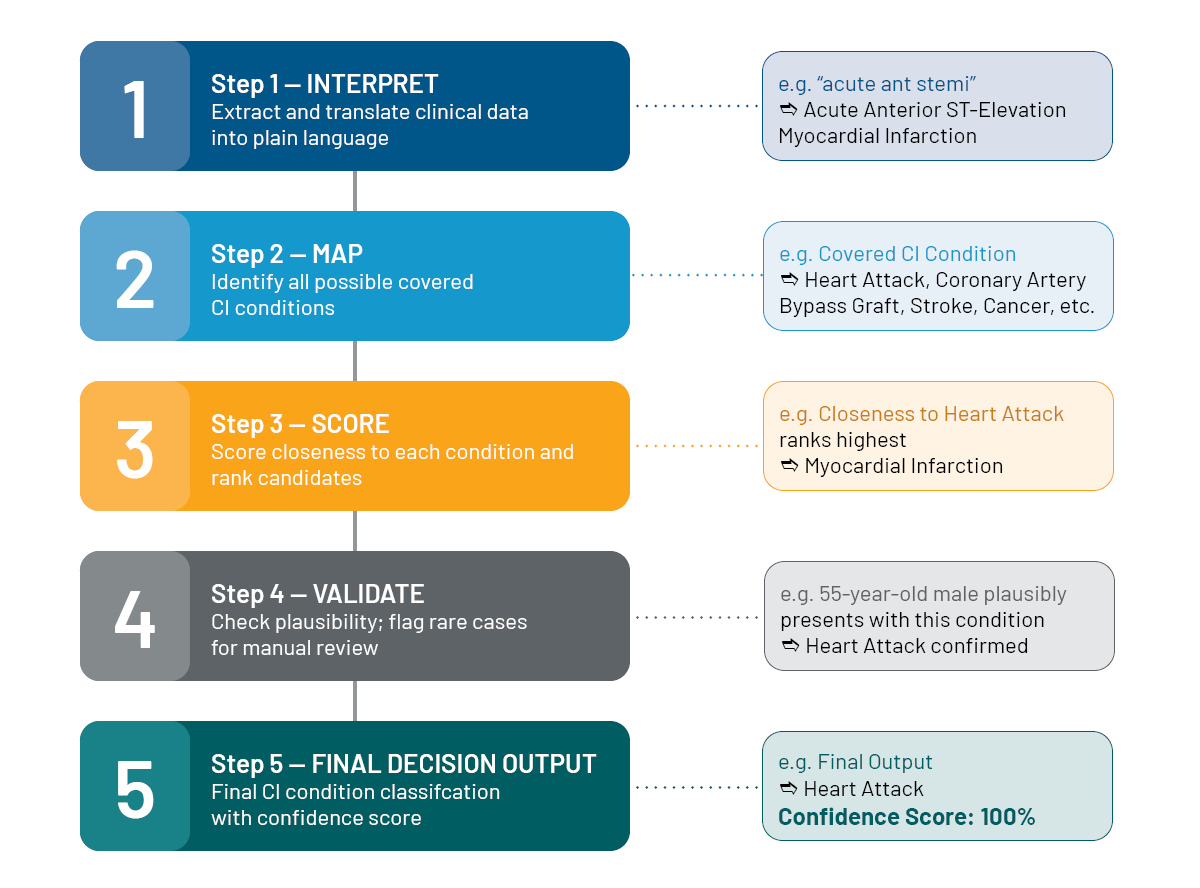
We now have a multi-agent workflow that provides a structured breakdown that reduces hallucinations, improves consistency, and increases transparency in a way that is both intuitive and auditable. This architecture reflects the way actuaries and claims professionals naturally approach CI assessment – breaking down a complex judgemental task into clear components.
It offers several benefits:
- Reduced hallucinations through narrowly defined scopes
- Improved auditability by making each step explicit
- Modularity, allowing each agent to be tested or improved independently
- Human friendly traceability showing exactly how the conclusion was formed
- Compliance alignment with actuarial and regulatory expectations for explainability
This workflow transforms generative AI from a “black box predictor” into an explainable, governed, and traceable decision-support partner.
Reliability by Design – Evaluation and Governance of Generative AI
AI reliability has been a primary focus of regulators and policy-setters in the financial sector,2 with much attention given to how it can be deployed in a stable, trustworthy manner. Considerations such as bias, fairness, explainability, transparency, and interpretability are all important when implementing generative AI solutions. However, reliability should not be viewed as a feature of the model alone. Rather, it is a property of the entire workflow in which the model operates. A robust generative AI solution therefore requires not only well-designed agents, but also disciplined evaluation, governance, and continuous monitoring of the entire workflow.
One important safeguard is the establishment of a human-in-the-loop review framework. While agentic workflows can reduce error and improve consistency, human oversight remains essential.
To implement an efficient human-oversight framework, a predefined metrics suited to the use case can be set so that edge cases are routed to human review. Given that there is no universal standard for what proportion of generative AI outputs should be reviewed by humans, this framework can help organisations adopt thresholds that are appropriate to their risk appetite and operational needs.
For example, during the testing phase, confidence scores can be assessed on a validation dataset to determine the level below which outputs should be flagged for human review. Additional review rules may also be introduced for terminology that is uncommon, novel, or particularly sensitive to error and bias. In the CI claims classification context, this may include low-confidence classifications, unfamiliar medical terminology, contradictory or ambiguous extracted features, and claims that fall outside known data distributions.
More deterministic metrics can also be incorporated. For instance, in a classification setting, cosine similarity (a measure of the angle between two vectors that captures direction independent of magnitude, so two texts of very different lengths can still register as similar if their feature distributions point the same way) between wording embeddings may be monitored, with cases falling below a specified threshold escalated for review. With careful methodology, generative AI supports, rather than supplants, professional judgement.
A second component of reliability is the creation of a rigorous validation pipeline supported by a “golden dataset” and other known non-generative AI‑dependent metrics. A golden dataset in this context refers to a curated set of high-quality and often hand-labelled data that contains the “ground truth” which the generative AI system is expected to be tested against. This dataset should be sufficiently large and diverse to reflect the range of practical scenarios the workflow may encounter, and it should be retained for ongoing testing as the solution evolves.
Although time-consuming to build, a golden dataset is central to a multi-layered evaluation workflow of a generative AI system. In the CI claims classification example, the multi-layered evaluation workflow may include back-testing against the golden dataset curated from historical claims descriptions, comparison with representation-based natural language processing methods such as embedding models or encoder models such as BERT (Bidirectional Encoder Representations from Transformers), statistical reasonableness and outlier checks, and adversarial testing using rare edge-cases or intentionally misleading descriptions.
Such a layered validation approach strengthens reliability and governance by ensuring that performance is tested from multiple angles rather than judged solely on headline accuracy.
Another useful mechanism is to use a stronger AI model to evaluate the output of another AI model. An independent generative AI agent can serve as an evaluation layer for the outputs produced by a smaller or less costly model used in production. This can be effective when stronger models with reasoning capabilities are guided through well-designed prompts to assess whether a result is plausible, complete, and aligned with expectations, while also assigning a confidence level for the evaluation. This creates a form of model-based quality assurance that can improve scalability without relying entirely on manual review. Nevertheless, human review remains necessary for cases where the evaluation agent identifies contradictions, uncertainty, or disagreement with the original output.
Transparent documentation of decisions is a fourth element. Clear documentation of prompts, model settings, reference materials, validation methods, escalation criteria, and workflow decisions supports auditability, reproducibility, and compliance with internal governance requirements. It also aligns closely with the actuarial profession’s emphasis on transparency, accountability, and professional judgement. In high-stakes insurance applications, documentation serves as a control that enables others to understand how and why a conclusion was reached. Moreover, as the field of generative AI continues to evolve rapidly, such documentation is essential for ensuring that enhancement and maintenance remain effective when changes occur that may affect the availability or performance of deployed models.
Finally, reliability depends not only on how a workflow is built, but also on how it is maintained over time. A simple and well-governed upgrading pipeline supports continued reliability. As models, prompts, product definitions, and source documents evolve, the workflow must be easy to update, retest, and redeploy in a controlled manner. A modular architecture is especially valuable for this purpose, as individual agents or components can be improved independently without disrupting the entire system. This allows organisations to continuously refine performance while preserving governance standards and maintaining confidence in the process.
Taken together, these practices shift generative AI from being an experimental tool to a dependable decision-support capability. By combining human oversight, golden dataset validation, model-based evaluation, transparent documentation, and controlled upgrade pathways, actuaries can design generative AI workflows that are effective, explainable, auditable, and aligned with enterprise risk management expectations.
Summary
As the AI landscape continues to evolve, the range of tasks the technology can support to improve productivity has expanded. Limitations that once made organisations cautious about adopting AI are increasingly being overcome as the technology matures.
Generative AI can deliver more value in insurance when it is engineered to reason the way actuaries work. This article has set out two connected arguments. First, decomposing a complex judgemental task into a sequence of specialised agents mirrors how actuaries break down and evaluate a problem, reducing hallucination and improving auditability. Second, reliability is a property of the entire workflow rather than the model alone, earned through human oversight, golden-dataset validation, model-based evaluation, transparent documentation, and controlled upgrades. Although illustrated through CI claims classification, these principles give actuaries a repeatable framework for building robust, explainable, and scalable AI‑enabled solutions, positioning them not as adopters of these tools but as the people who design and govern them.
Speak to your Gen Re associate today to learn how we can help implement AI‑enabled solutions across the insurance value chain.
Endnotes
- IBM, What are AI hallucinations?, https://www.ibm.com/think/topics/ai-hallucinations
- Monetary Authority of Singapore, Consultation Paper on Proposed Guidelines on Artificial Intelligence Risk Management for Financial Institutions, https://www.mas.gov.sg/publications/consultations/2025/consultation-paper-on-guidelines-on-artificial-intelligence-risk-management
See also: EU Artificial Intelligence Act, Regulation (EU) 2024/1689, OJ L 2024/1689, 12.7.2024, https://eur-lex.europa.eu/eli/reg/2024/1689/oj